

3 Pragmatic Differences Between Academic And Production Software Libraries
Choosing the right AI library is crucial for success. Academic libraries prioritize reproducibility, while industry-focused libraries prioritize production-grade code.

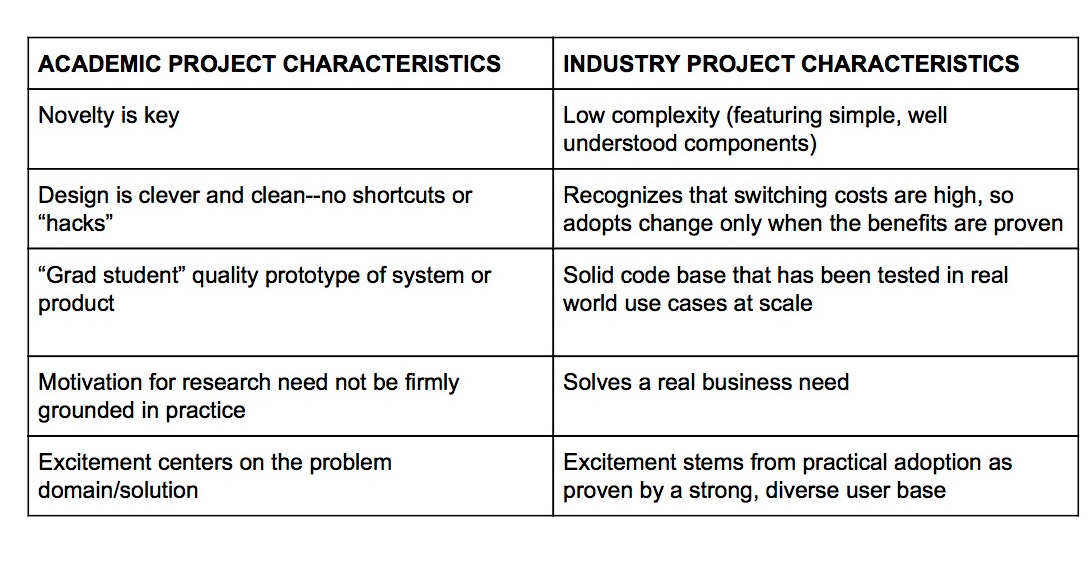
Starting a new AI project will often confront you with the paradox of choice: there are too many great libraries and models to start from. One way to avoid analysis paralysis due to feature-by-feature comparisons is to focus on tools that were designed for your kind of project.
At my company, John Snow Labs, we often get compared to Allen NLP, Stanza, SciSpacy, and other libraries focused on academic use cases. Many AI libraries started in academia to help researchers write papers faster, while others were created specifically to help enterprises build production systems.
These are very different communities which result in different design decisions and priorities. Some academic libraries may indeed go on to become mainstream, but there are fundamental differences that should be considered depending on your goals.
Reproducibility Vs. Freshness
Models perform differently on academic datasets versus real-world data. In industry, you need current, state-of-the-art models to succeed, and these models have to be regularly updated.
Take BioBERT, a pre-trained biomedical language representation model for biomedical text mining. This is an adaptation of BERT (Bidirectional Encoder Representations from Transformers), a neural network-based technique for natural language processing (NLP) pre-training, specifically for biomedical use cases. You want BioBERT pretrained on a regular basis on the latest research, not only on general English but biomedical language.
BioBERT was trained in early 2019—and as we know, a lot has happened in healthcare and society since then. BioBERT considers “Covid-19” to be an unrecognized, out-of-vocabulary keyword. This isn’t a problem if you’re only using BioBERT to reproduce old papers and results—in fact, having a frozen model is a requirement for such reproducibility—but imagine using such a model in a production system?
Medical terminologies and practices keep evolving: If you have a model that identifies drug names in a medical text, you need it updated nearly weekly in order to track new drugs that come to market. The same goes for diseases, procedures, medical devices, biomarkers, antibodies, surgical techniques, and other terms.

Production-Grade Codebase Vs. Fast Prototyping
Production-grade software implies code that has strong test coverage, automated CI/CD infrastructure, regular tests for security vulnerabilities, a release process that ensures that faulty or malicious software can’t be slipped into the codebase, and a focus on optimizing speed, memory consumption, and compatibility with major cloud providers and compute platforms. In contrast, research frameworks are focused on speed of prototyping, which leads to very different software designs and processes.
For example, in October 2021, researchers from Google introduced SCENIC, an open-source JAX library with a focus on Transformer-based models for computer vision research. Its aim is to make large-scale model prototyping faster and thus easier for people to make small changes and write papers.
Historically, research libraries like SCENIC have been very successful at prioritizing rapid prototyping. This enables the creation of product simulations for testing and validation during the product development process.
Here is the "Philosophy" section from the project’s GitHub homepage: “Scenic aims to facilitate rapid prototyping of large-scale vision models. To keep the code simple to understand and extend, we prefer forking and copy-pasting over adding complexity or increasing abstraction. Only when functionality proves to be widely useful across many models and tasks, it may be upstreamed to Scenic's shared libraries.”
SCENIC has been successful precisely because it has made explicit trade-offs to achieve its goal—helping researchers move faster instead of building a reusable and well-abstracted codebase. It’s another example where an academic-focused library is not fit for production systems, not because it’s poorly designed but because it is well designed and managed to achieve a different goal.
Roadmap Prioritization
A third major difference between academic- and industry-focused libraries is what they prioritize. For example, in an academic setting, you’ll want to run it against other standard academic benchmarks when you train a new model. Being able to run your model versus the entire SuperGLUE benchmark for natural language understanding in one line of code and easily reproducing results from other models on different metrics is an amazing feature. Having additional helper scripts that organize the output and provide detailed comparisons to other models is also very useful.
In contrast, enterprise customers don’t care about this. They care about reliability, scalability, cost, security, and compliance. What type of data will you have to share to get your AI project off the ground, and what protective measures are in place? Do they meet regulations such as GDPR, CCPA, or industry-specific laws like HIPAA? How will you factor in explainability and avoid bias or concept drift over time? How will monitoring take place? What are the versioning and release processes, and do they integrate with enterprise-wide tools? How would the processes of training, tuning and inference of the model integrate as part of the overall enterprise architecture?
Two Communities, Two Needs
Ultimately, there are major technical gaps between building a model and getting it ready for use in real-world products and services. It is also largely a software engineering effort, not a data science effort, and the right skill sets must be involved.
In practice, there are two different communities that need to be served—those in academia and those in industry. For enterprise AI users especially, it would seem that picking the right library before the right tool is the best way to ensure your AI projects have the greatest chance of success.