

3 Reasons for Low User-Perceived Accuracy of AI Models
This article explores the disparity between model accuracy metrics and customer satisfaction, highlighting differing interpretations, labeler disagreements, and overlooked biases.

Suppose you’re asked to develop a machine learning model that classifies "urgent" emails from the rest. The most important metric for your customers is precision -- that is, if your models states that an email is urgent, it should actually be urgent. You build an outstanding model that is 99% precise, measured on a validation data set that is blind, representative, unbiased and large enough. After triple-checking your numbers, you confidently go to market to a vocal chorus of ... disappointed customers, who tell you unequivocally that your model is just not that precise.
What happened?
This is a common occurrence when AI models get to market: Internal accuracy numbers just don’t translate to what customers experience. This naturally leads to lost sales, a partially damaged reputation and delayed deployments. Internally, this leads to a loss of confidence in the accuracy reported by the data science team. This then leads to a slow and cautious rollout of new AI products, putting the company further behind its faster competitors.
Same Words, Different Meanings
The first reason for why this may happen is simple: Each of your customers has a different opinion on what an “urgent” email is. This, of course, applies to whichever AI problem you’re attacking -- identifying fraudulent wire transfers, high-risk patients, high-value customers or end-of-life machines. Every team in every company has its own take on what these fuzzy terms mean.
You’re facing this challenge if different customers grade your models differently. Hearing in the same week from three different customers that they measure your model to be 30%, 60% and 90% accurate may drive your sales team crazy, but it just means that they measured different things.
To help your customers measure your precision and evaluate your model, share with them the guidelines you’ve written, and propose best practices for minimizing disagreements among their own labelers. Another approach is to propose a two-stage evaluation: Start with a baseline measurement of your out-of-the-box model, and then re-evaluate on a tuned model -- once you’ve had the opportunity to retrain it based on this specific customer’s guidelines.
If you’re a buyer of such models, make sure to take these actions and communicate exactly how you evaluated each model. Otherwise, your own organization might blame you for buying a crappy model after you have validated its precision yourself.
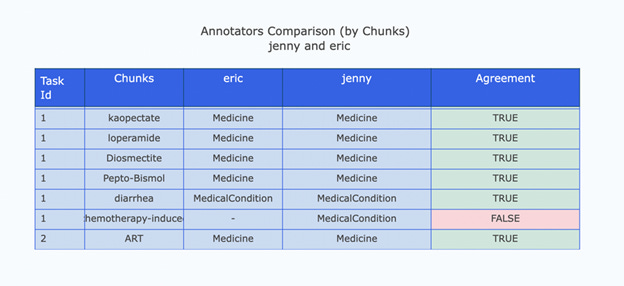
Disagreement Between Annotators
A second reason for your internal accuracy metrics being inaccurate is a disagreement between your labelers. This happens when you have multiple people labeling or when the labels are crowdsourced. Going back to our urgent emails example, if you were to send the exact same set of emails to your labeling team or crowd again, would 100% of the emails still get the same label (i.e., urgent or non-urgent)? If the number is 90%, then 90% is the upper bound of what your real precision can be. Anything above that is, by definition over-fitting to the random choices that labelers made when you just asked.
You’re facing this problem if your own internal accuracy measurements change drastically when you update your validation set. Getting wildly different accuracy measurements for different subsets of your validation set is also a good sign.
This problem is easy to measure: Just count the ratio of disagreements between your labelers. Doing this is fully within the control of a data science team and should be considered an imperative best practice. Minimizing labeler disagreement takes work, too: writing guidelines, training labelers, asking for multiple labels, and regularly discussing disagreements within the team.
Overlooked Bias
A third cause is assuming that customers care about your unbiased and representative measurement.
While you have painstakingly collected every type of corporate email to make sure that your training and validation data sets are complete, representative and unbiased, each end user cares about their own inbox. If I’m a payroll specialist, my urgent emails are about employee onboarding and offboarding. If I’m in shipping, my urgent emails are about stuck shipments and missing trucks. If I’m in customer service, urgency usually involves escalations. Whoever I am, my set of emails is highly skewed and biased.
Assume that an organization sends a million emails per day, but only 100,000 of those are sent to the customer service team, which makes up half of all employees. It could well be the case that your model classifies 95% of all urgent emails correctly but only 70% of customer-service-related emails correctly. In that case, while your overall precision is 95%, half of all users are experiencing 70% precision.
If this challenge sounds a lot like “classic” AI bias, it’s because it is. Replace “customer service team” with “women” or “candidates over 50 years old,” and you have a different modeling problem. The technical tools for addressing this issue are similar, too. The main thing you must do is be aware of and measure this problem in advance. Keep in mind that “95% accurate” can be very different from “95% of users are experiencing 95% accuracy.”
This post described the top three causes for reporting incorrect model accuracy based on actual projects I’d been involved with over the past decade. Selecting these “top three” reasons is therefore skewed by my own limited experience. I would appreciate it if you could educate me by reaching out and sharing other causes and preventive measures you’ve taken to address this common issue.