

Applying Responsible NLP in Real-World Projects
The underlying principles behind the NLP Test library: Enabling data scientists to deliver reliable, safe and effective language models.

Responsible AI: Getting from Goals to Daily Practices
How is it possible to develop AI models that are transparent, safe, and equitable? As AI impacts more aspects of our daily lives, concerns about discrimination, privacy, and bias are on the rise. The good news is that there is a growing movement towards Responsible AI with the goal of ensuring that models are designed and deployed in ways that align with ethical principles, which include [NIST 2023]:
Validity and Reliability: Developers should take steps to ensure that models perform as they should under a variety of circumstances.
Security and Resiliency: Models should show robustness to data and context that is different than what they were trained on or different than what is normally expected. Models should not violate system or personal security or enable security violations.
Explainability and Interpretability: Models should be capable of answering stakeholder questions about the decision-making processes of AI systems.
Fairness with Mitigation of Harmful Bias: Models should be designed to avoid bias and ensure equitable treatment of all individuals and groups impacted by the data. This includes ensuring the proper representation of protected groups in the dataset.
Privacy: Data privacy and security should be prioritized in all stages of the AI pipeline. This includes both respecting the rights of people who do not wish to be included in training data, as well as preventing leakage of private data by a model.
Safety: Models should be designed to avoid harm to users and mitigate potential risks. This includes model behavior in unexpected conditions or edge cases.
Accountability: Developers should be accountable for the impact of their models on society and should take steps to address any negative consequences.
Transparency: Developers should be transparent about the data sources, model design, and potential limitations or biases of the models.
However, today there is a gap between these principles and current state-of-the-art NLP models.
According to [Ribeiro 2020], the sentiment analysis services of the top three cloud providers fail 9-16% of the time when replacing neutral words, and 7-20% of the time when changing neutral named entities. These systems also failed 36-42% of the time on temporal tests and almost 100% of the time on some negation tests. Personal information leakage has been shown to be as high as 50-70% in popular word and sentence embeddings, according to [Song & Raghunathan 2020]. In addition, state-of-the-art question-answering models have been shown to exhibit biases around race, gender, physical appearance, disability, and religion [Parrish et. al. 2021] – sometimes changing the likely answer more than 80% of the time. Finally, [van Aken et. al. 2022] showed that adding any mention of ethnicity to a patient note reduces their predicted risk of mortality – with the most accurate model producing the largest error.
These findings suggest that the current NLP systems are unreliable and flawed. We would not accept a calculator that correctly works at a particular time or a microwave that randomly alters its strength based on the type of food or time of day. Therefore, a well-engineered production system should work reliably on standard inputs and be safe & robust when handling uncommon ones. The three fundamental software engineering principles can help us get there.
Software Engineering Fundamentals
Testing software is crucial to ensure it works as intended. The reason why NLP models often fail is straightforward: they are not tested enough. While recent research papers have shed light on this issue, testing should be standard practice before deploying any software to production. Furthermore, testing should be carried out every time the software is changed, as NLP models can also regress over time [Xie et. al. 2021].
Even though most academics make their models publicly available and easily reusable, it is not recommended to reuse academic models as production-ready ones. It is because tools that are designed to reproduce research results may not be suitable for production use. This makes research faster and enables benchmarks like SuperGLUE, LM-Harness, and BIG-bench. Reproducibility requires that models remain the same rather than being continuously updated and improved. For example, BioBERT, a commonly used biomedical embedding model, was published in early 2019 and did not consider COVID-19 as a vocabulary word due to its release date. This illustrates how relying solely on academic models may hinder the effectiveness of NLP systems in production environments.
It is important to test beyond accuracy in your NLP system. This is because the business requirements for the system include robustness, reliability, fairness, toxicity, efficiency, lack of bias, lack of data leakage, and safety. Therefore, your test suites should reflect these requirements. A comprehensive review of definitions and metrics for these terms in different contexts is provided in the Holistic Evaluation of Language Models [Liang et. al 2022], which is well worth reading. However, you will need to write your own tests to determine what inclusiveness means for your specific application.
Your tests should be specific, isolated, and easy to maintain, as well as versioned and executable so that they can be incorporated into an automated build or MLOps workflow. To simplify this process, you can use the nlptest library, which is a straightforward framework.
Design Principles of the NLP Test Library
Designed around five principles, the nlptest library is intended to make it easier for data scientists to deliver reliable, safe, and effective language models.
Open Source. It is an open-source community project under the Apache 2.0 license, free to use forever for commercial and non-commercial purposes with no caveats. It has an active development team that welcomes contributions and code forks.
Lightweight. The library is lightweight and can run offline (i.e., in a VPN or a high-compliance enterprise environment) on a laptop, eliminating the need for a high-memory server, cluster, or GPU. Installation is as simple as running pip install nlptest, and generating and running tests can be done in just three lines of code.

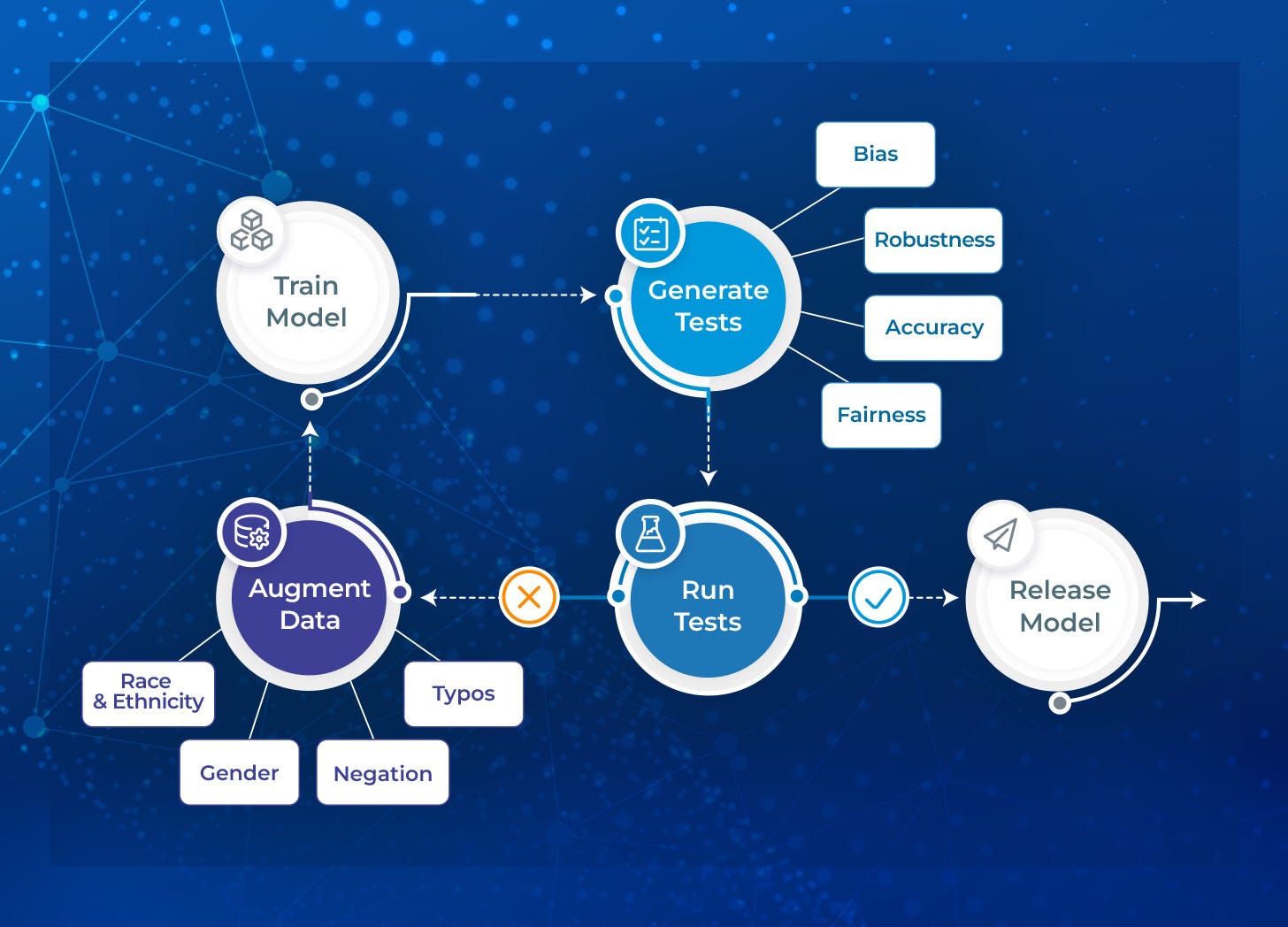
By importing the library, creating a new test harness for the specified Named Entity Recognition (NER) model from John Snow Labs’ NLP models hub, and running the code, the library automatically generates test cases ((based on the default configuration) and generates a report, simplifying the process for data scientists.
Storing tests in a pandas data frame makes it simple to edit, filter, import, or export them. The entire test harness can be saved and loaded, allowing you to run a regression test of a previously configured test suite simply by calling h.load(“filename”).run().
Cross Library. The framework provides out-of-the-box support for transformers, Spark NLP, and spacy, and can be easily extended to support additional libraries. As an AI community, there is no need for us to build the test generation and execution engines multiple times. It allows testing of both pre-trained and custom NLP pipelines from any of these libraries.

Extensible. Since there are hundreds of potential types of tests and metrics to support, additional NLP tasks of interest, and custom needs for many projects, much thought has been put into making it easy to implement and reuse new types of tests.
To support hundreds of potential types of tests and metrics, additional NLP tasks, and custom needs for many projects, the framework has been designed to be extensible, making it easy to implement and reuse new types of tests. For instance, the framework includes a built-in test type for bias in US English, which replaces first and last names with names that are common for White, Black, Asian, or Hispanic people. But what if your application is intended for India or Brazil, or if the testing needs to consider bias based on age or disability, or if a different metric is needed for when a test should pass?
The nlptest library makes it easy to write and then mix and match test types. The TestFactory class defines a standard API for different tests to be configured, generated, and executed. We’ve put in a lot of effort to ensure that the library can be easily tailored to meet your needs and that you can contribute or customize it with ease.
Test Models and Data. A common issue when a model is not ready for production lies in the dataset used for training or evaluation, rather than the modeling architecture. A widely prevalent issue in commonly used datasets, as demonstrated by [Northcutt et. al. 2021] is the mislabeling of training examples. Additionally, representation bias presents a challenge for assessing a model’s performance across ethnic lines, as there may not be enough test labels to calculate a usable metric. In such cases, it is appropriate for the library to fail a test and suggest changes to the training and test sets to better represent other groups, fix likely mistakes, or train for edge cases.
Therefore, a test scenario is defined by a task, a model, and a dataset, i.e.:

This setup not only allows the library to offer a complete testing strategy for both models and data but also enables you to use generated tests to augment your training and test datasets, which can considerably reduce the time required to fix models and prepare them for production.
The next sections describe that the nlptest library helps you automate three tasks: Generating tests, running tests, and augmenting data.
Getting Started
Ready to improve the safety, reliability, and accuracy of your NLP models? It’s time to get started with the John Snow Labs’ nlptest library by visiting nlptest.org and installing it with pip install nlptest. With its extensive support for different NLP libraries, extensible framework for creating custom tests, and ability to generate and run tests on both models and datasets, you can quickly identify issues and improve the accuracy of your models.
Join our open-source community project on GitHub, share examples and documentation, and contribute to the development of the library.