

Three Healthcare AI Frameworks, one governance backbone: RUAIH, URAC, and CHAI
U.S. healthcare now has two AI certifications and a set of governance playbooks, but they all rest on one backbone you must sustain.

In about a year, U.S. healthcare went from having no shared way to govern AI to having two certifications and a detailed set of governance playbooks. URAC published its Health Care AI accreditation. The Joint Commission, with CHAI, launched the Responsible Use of AI in Healthcare (RUAIH) certification. And CHAI released governance playbooks that spell out the baseline controls the Joint Commission’s certification is built to (CHAI doesn’t certify anyone). To a health system looking at all three at once, it still reads like three separate programs with three separate binders. It isn’t. Underneath, they describe the same governance structure, and the expensive mistake is to build it three times. This post covers what each one asks for, what they share, and why sustaining any of them across a real AI portfolio is a problem you solve with automation rather than headcount.
The Joint Commission’s Responsible Use of AI in Healthcare (RUAIH) Certification
The Joint Commission’s Responsible Use of AI in Healthcare certification, announced June 1, 2026, is the first U.S. certification for how a healthcare organization uses AI. It’s voluntary, open to more than 22,000 hospitals, critical access hospitals, and health systems, and you don’t need an existing Joint Commission accreditation to apply. Jonathan Perlin, the Joint Commission’s CEO, put the rationale in plain terms: more than 80% of physicians already use AI in their work, and there has been no shared standard for doing it responsibly.
RUAIH is built around five standard areas: governance, effective data management, risk and bias reduction, monitoring and validation of safety and performance, and transparency, education, and training. The detail that shapes how you prepare is that it certifies your organization rather than your products. There is no “certified” tool you can buy your way in with; a surveyor looks at how you govern, monitor, and stay accountable for AI across your whole estate. And four of those five areas describe work that never stops, which turns out to be where the difficulty lives.
The Utilization Review Accreditation Commission (URAC) Health Care AI Accreditation
URAC actually got there first, releasing its Health Care AI accreditation in 2025 as the first of its kind. It takes a structure RUAIH doesn’t, with two separate paths: one for the organizations that deploy AI, and one for the developers that build it. The standards pair core modules that any accredited organization has to meet, covering risk management, operations and infrastructure, and performance monitoring and improvement, with a users module that asks for an AI management plan, an annual evaluation of outcomes, testing and monitoring done in the organization’s own setting and on its own population, training for the people who rely on the system, an appropriate-use assessment, and disclosures of where AI is in play.
What URAC validates is real operation. Accreditation runs on interviews and system assessments rather than a paperwork review, and the users module is explicit that the testing and monitoring have to happen in your environment, on your case mix. As with RUAIH, URAC is careful about its limits: it doesn’t certify that a given AI product is safe or that your use of it is legal. It attests that the program around the AI is real and running.
The Coalition for Health AI (CHAI) Governance Playbooks
CHAI is the piece people most often mislabel: it’s a consensus body, not a certifying or regulatory one. It doesn’t grant a credential and it doesn’t impose requirements. What it does is convene the field, more than 3,000 member organizations, and publish guidance the field agrees on. On May 27, 2026, it released its governance playbooks, developed with input from 150-plus health AI leaders across more than 100 healthcare organizations, from academic medical centers to community health centers.
The playbooks define baseline controls for responsible AI use and give organizations examples, implementation guidance, tools, and resources to put those controls into practice. They cover eight elements: AI Policy; Organizational Structures; Organizational Resources; Responsible AI Lifecycle Management and Use; Risk and Impact Assessments; Responsible Data Management and Use; Third Party Management; and Education, Training, and Feedback. CHAI is deliberate that the playbooks are a baseline to adapt to each organization’s context, not a mandate.
CHAI states that the playbooks provide a framework to achieve the voluntary certification the Joint Commission has now released, and the Joint Commission and CHAI co-developed the underlying guidance together. So building your program to the CHAI playbooks is building to the controls RUAIH assesses, and to most of what URAC asks for as well. The guidance does double duty before you have even chosen which certificate to pursue.
All three share one governance backbone
Set them side by side and the overlap is hard to miss. Each one asks for governance with named accountability, control over the data feeding AI, evaluation and mitigation of bias, validation before deployment, monitoring after it, transparency and training for the people in the loop, and discipline around third-party tools. The wording differs and the grouping differs, but it’s one set of requirements described three ways.
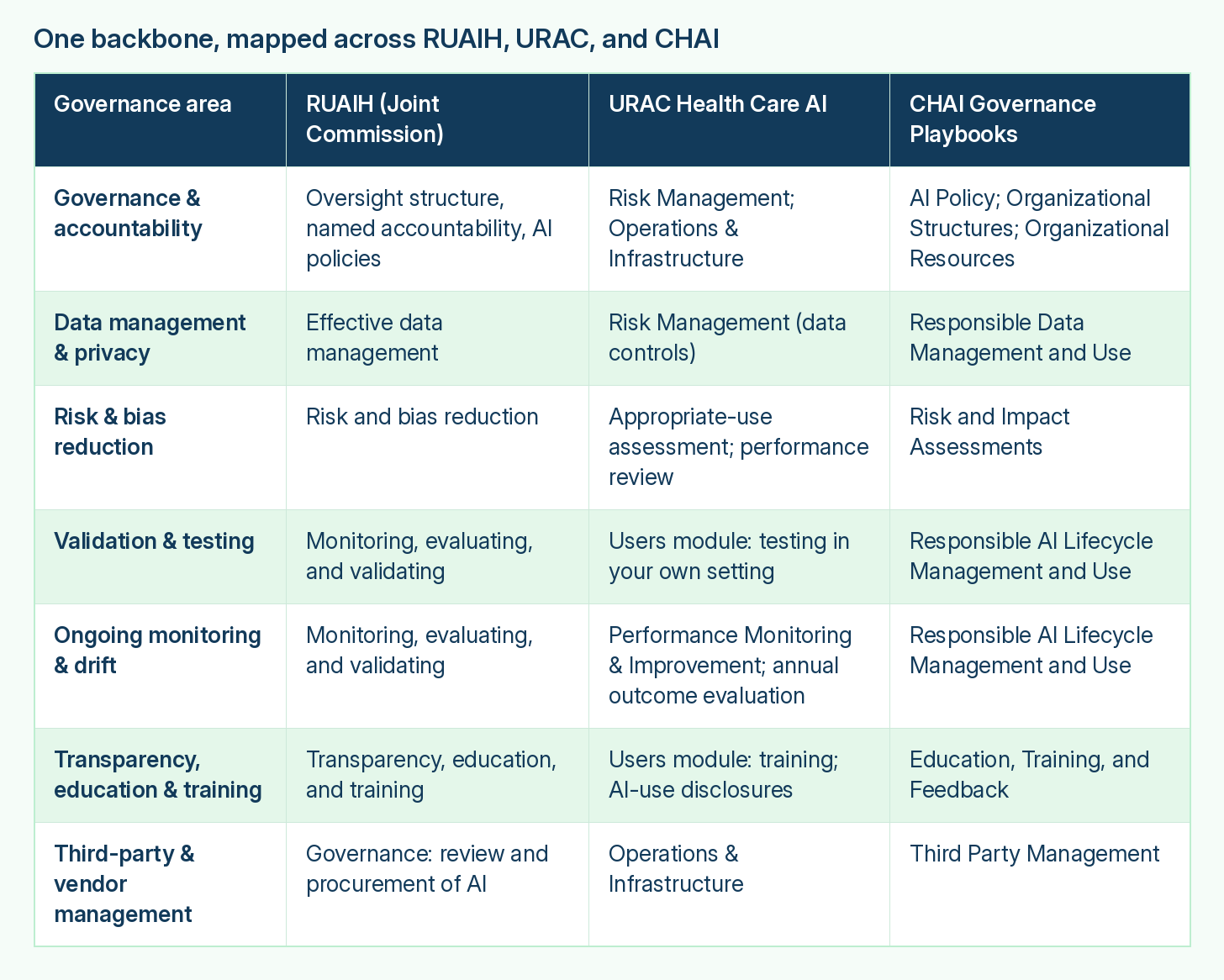
This means you build the program once: the work that satisfies one of these satisfies most of the others. The same backbone is what the horizontal frameworks check for too, including the NIST AI Risk Management Framework and ISO/IEC 42001. The other obligations are healthcare-specific state laws, like Texas SB 1188 and California SB 1120, and federal regulations, like HHS HTI-1 and ACA Section 1557. You want one program that meets all of them from the same evidence.
Sustaining a certification is harder than earning it: volume, drift, and evidence
If the backbone is shared, why is any of this hard? Because four of those areas are continuous, and continuity is where governance programs quietly come apart. A motivated health system can assemble the artifacts for an initial survey in a few weeks: a charter, a policy set, a handful of model cards, a risk register. Keeping them true a year later is the real test, and three forces work against it.
The first is volume. A modern health enterprise runs dozens to hundreds of AI systems, much of it arriving through existing vendors or showing up as point solutions nobody logged. A 2025 Elion survey found AI submissions outrunning governance decisions by nearly 3 to 2, with most programs staffed by two or fewer dedicated people. The AI portfolio grows much faster than the team reviewing it.
The second is drift. Models drift as their inputs shift, vendors push updates you didn’t schedule, and the regulatory picture moves under you, sometimes inside a single quarter. A monitoring program that was accurate on survey day can be stale by the next board meeting.
The third is the nature of the evidence. A surveyor doesn’t want a policy that says you monitor for bias; they want the dated test results, the drift reports, and the documented reviews that show you actually did, and that they’re current. Producing that proof once is straightforward. Producing it continuously, across every system, is the part that breaks small teams. A January 2026 CHAI patient survey run by NORC at the University of Chicago found that more than 80% of patients would trust healthcare more with clear accountability in place, and that they’re specifically wary of AI running without human oversight. The certifications address that worry, but only if the answer holds up every day rather than once.
Automation: the risk assessments, model cards, and vendor reviews
“Automation” is an overused word every governance vendor now reaches for, so it’s worth being specific about what must be automated for the math to change. It’s the analysis, not the filing. A committee that meets twice a month and a compliance team of three cannot hand-write a risk and impact assessment for every system, draft a model card for each one, read each vendor’s AI disclosures to score its risk, run the pre-release tests, and watch production for drift, across hundreds of systems continuously. The useful kind of automation does more than manage workflows and store documents. It reads the documentation, maps it to the frameworks, and produces full drafts: a model card from the project’s own documentation, a vendor risk score with the justification spelled out, a proposed risk tier and set of controls for each system on the register. People review, adjust, and approve, which is what responsible governance requires anyway.
That’s the line between governance automation and governance theater. The document-and-workflow tools most organizations already own hand your team blank templates and reminders, then wait for your people to do the actual thinking. An automation layer does the thinking first, from material it has read, and gives your experts something to correct instead of a blank page.
For example, here is how the Pacific AI platform maps onto the shared backbone, with the same evidence feeding RUAIH, URAC, and the CHAI playbooks at once. Full disclosure: I’m the CEO of Pacific AI and of John Snow Labs, so read what follows as the example I know best rather than the only way to do it.
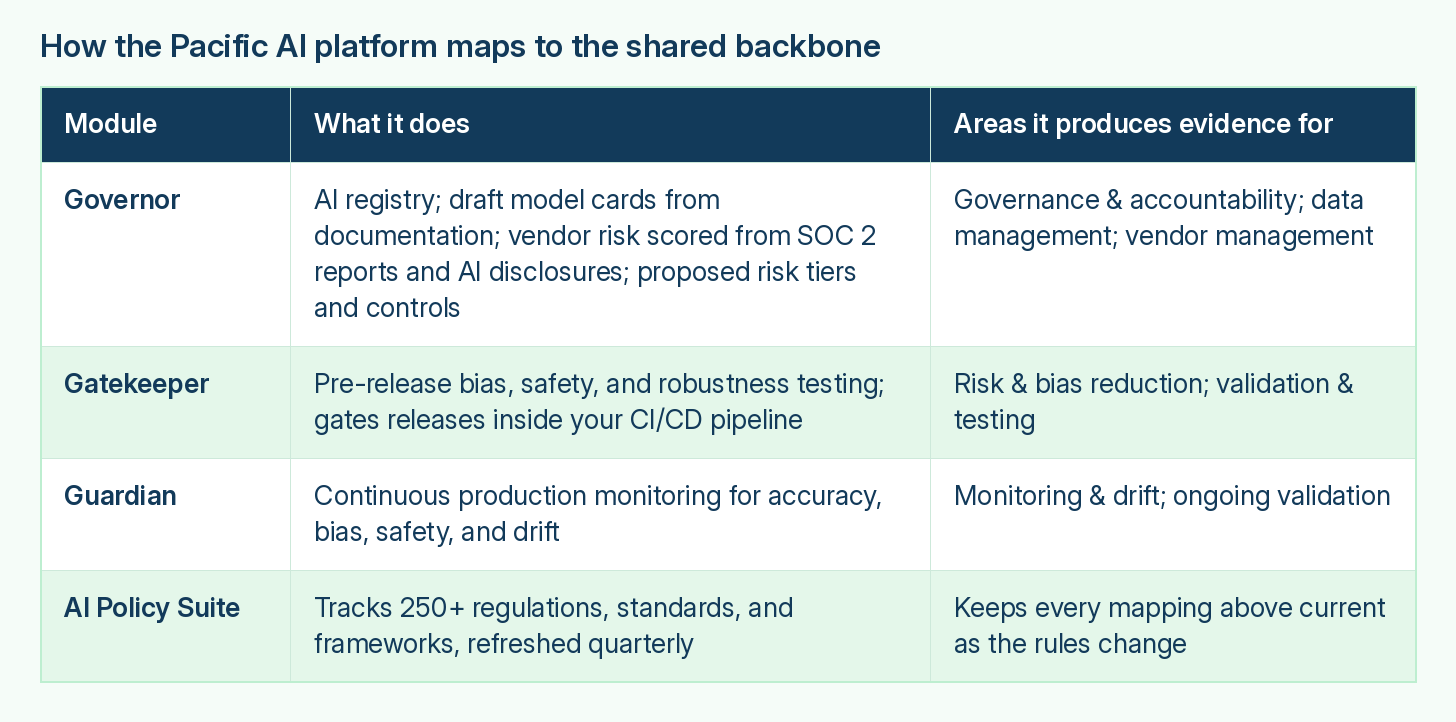
Pacific AI provides one platform that maps to RUAIH, URAC, and more than 250 regulations, standards, and frameworks: the healthcare-specific ones together with NIST, ISO, and the federal and state AI laws, refreshed every quarter. You don’t chase each rule on its own, and more importantly, you don’t chase the updates: when new regulations come out or standards change, the platform updates the mappings. So instead of retraining your team on each change, your automated risk evaluation, validation, and monitoring expand to cover it. That is often the most valuable part of automation from an ROI perspective, given how much enterprise-wide manual labor it replaces.
The economics: manual governance scales with headcount, automation with credits
A manual program’s cost is roughly the number of AI systems, times the evidence each one needs, times how often that evidence has to be refreshed. It’s bounded by how many trained governance people you can hire and keep. Double the portfolio and you double the work, but you can’t double a three-person team on demand, so the program doesn’t get visibly more expensive. It just stops keeping up: systems go un-reviewed, monitoring goes stale, and the gap between what’s deployed and what’s actually governed widens quarter over quarter. A 2026 study, the landscape of AI implementation in US hospitals, found that among hospitals running predictive models, 47% reported no accuracy evaluation and more than half reported none for bias.
Automation cuts the link between portfolio size and headcount, because the marginal system costs a few credits to assess and monitor instead of a new hire. Those two cost curves don’t hold a fixed distance apart; they diverge, and diverge fast as you scale.
This is why Pacific AI’s Platform Core is free, with unlimited users, systems, vendors, policies, and audit trails, and you pay only for the AI-enabled work such as risk assessments, test runs, and monitoring jobs. It installs inside your own AWS or Azure environment in about ten minutes, single-tenant, with no data leaving your VPC. There’s no multi-month implementation and no capital project standing between you and a working enterprise AI governance platform today.
Whichever way you implement AI governance, the economics have to work: the solution has to be cheap and fast. Those are relative to the cost of the system, but even outside a budget-cutting environment, a $100k-a-year AI system can’t require $50k a year to govern. $5k a year is more realistic, and that’s only achievable with real automation.
For organizations that would rather have help standing the program up, Pacific AI recently added a dedicated RUAIH certification-readiness advisory mapped to all five standard areas, which I believe is the first offering of its kind. It stands up the registry and risk tiers, documents the data controls, runs the pre-release testing, deploys continuous monitoring, and produces the disclosures and training materials, so the same engagement prepares everything you need to apply. That’s a six-to-twelve-week engagement, not a six-to-twelve-month one.
Whether you prepare for certification yourself or with outside help, remember that the certifications are awarded by the Joint Commission and by URAC, and no software grants them. CHAI doesn’t certify anything at all, since its playbooks are guidance. Automation produces and sustains the evidence those bodies look for, but it isn’t a substitute for the published standards or for your own legal counsel. That’s why human review and approval stay in the loop on every consequential decision: a program that produces evidence nobody trusts is worthless.
What to do now: build the backbone once and automate what won’t scale with manual effort
If you’re staring at three frameworks, the move is to stop seeing three. Pick the backbone, the seven areas in the table above, written to the CHAI playbooks since that’s the guidance both certifications lean on, and build it once. Automate the four continuous areas first, because those are the ones that decay between surveys and sink programs in year two. Model the marginal cost of your next AI system before your portfolio doubles, because the headcount math is the constraint that will actually bind. Then earn whichever certificate your board cares about most this year, knowing you’re most of the way to the other one already, and that the monitoring you stood up to stay certified is the same monitoring that keeps all of them current the year after.
FAQ
Are these frameworks mandatory?
No. RUAIH and URAC’s Health Care AI accreditation are both voluntary certifications, and the CHAI playbooks are voluntary guidance. They’re becoming competitive signals to patients, partners, and payers rather than legal requirements, though the obligations underneath them often overlap with rules that are mandatory, such as HHS HTI-1, ACA Section 1557, and state laws like California’s SB 1120.
Is CHAI a certification?
No, and the distinction matters to CHAI. It’s a consensus organization that publishes voluntary guidance, including the May 2026 governance playbooks. It doesn’t certify organizations or products and doesn’t impose requirements. Its playbooks describe baseline controls that the Joint Commission’s voluntary certification is built to, which is why building to them positions you well for RUAIH.
Do I have to choose among RUAIH, URAC, and the CHAI playbooks?
No. The playbooks are the shared guidance underneath, so building to them positions you for both certifications. RUAIH and URAC have different emphases. URAC has a developer path and validates operation in your own setting, while RUAIH is organization-wide governance. But the program you build underneath is largely the same.
Does any of this certify a specific AI product?
RUAIH explicitly does not; it certifies the organization. URAC has a developer path that assesses how a system was built, but neither one lets you buy a “certified” tool and inherit the credential. You’re certified for how you govern, test, and monitor.
What’s the hardest part of staying certified?
The continuous areas. Monitoring, bias review, validation, and training have to keep producing current, dated evidence long after the survey, across every system in the portfolio. That’s a volume-and-drift problem, which is why a small team needs automation to keep up.
Where does automation actually help, beyond being software?
In the analysis, not the filing. The useful kind reads your documents and drafts the risk assessment, the model card, and the vendor risk score, then runs the tests and monitors production continuously, so your experts review first drafts instead of authoring everything by hand. Tools that only store documents and send reminders are the governance-theater version; they don’t touch the work that scales badly.
How does the cost work if the platform is free?
The Pacific AI platform itself, including the registry, the policies, the audit trails, and unlimited users and systems, is free. You pay per unit of AI-enabled work, meaning a risk assessment, a test run, or a monitoring job. That keeps the marginal cost of governing one more system low enough that a growing portfolio doesn’t demand a linearly growing team. It also ensures that every action you pay for has an immediate, visible ROI.