

What healthcare already knows about shipping AI that other regulated industries haven’t figured out yet

Originally published March 2024 in CIO and Multilingual.
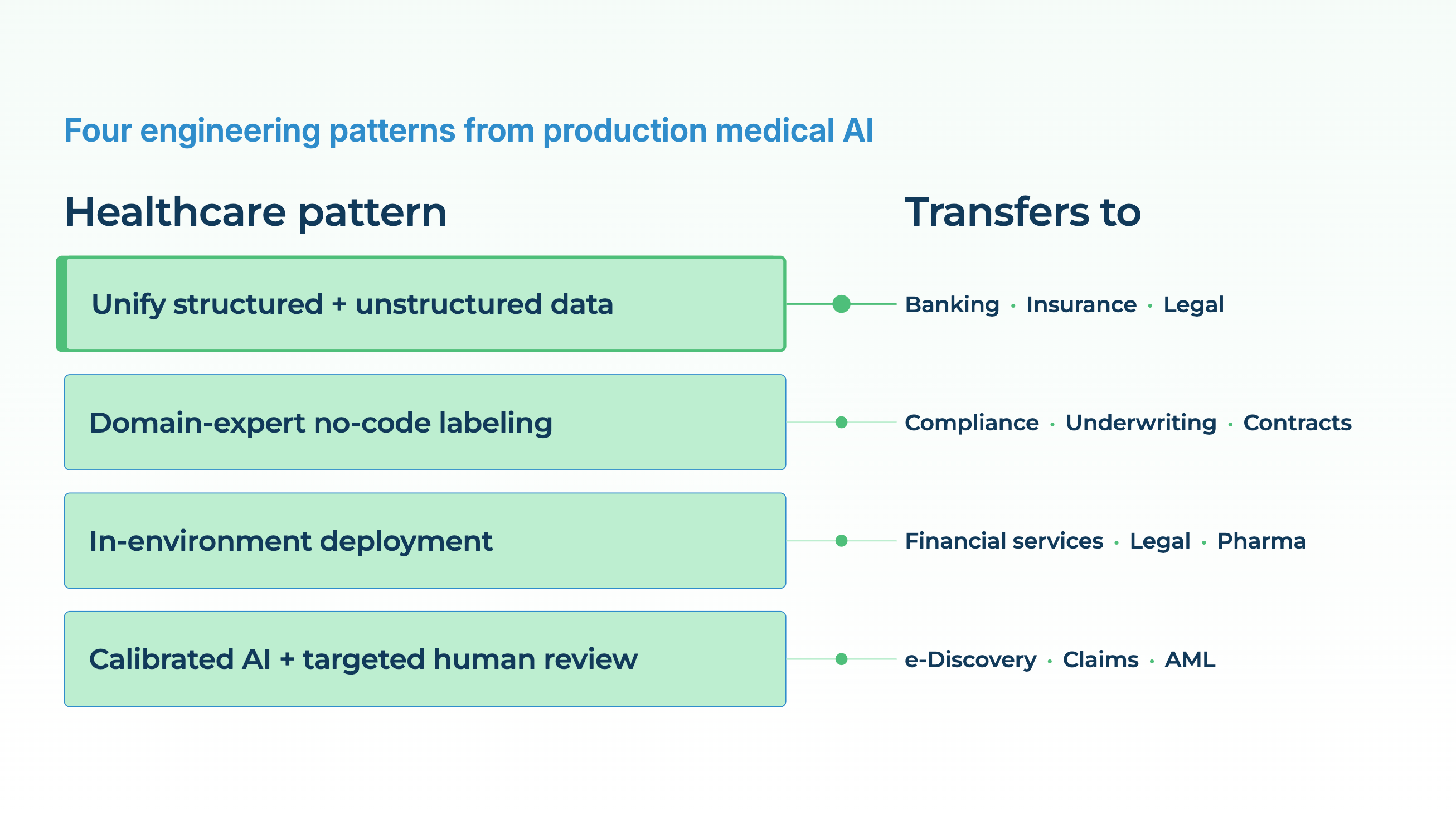
Healthcare got a head start on regulated AI because it had no choice. By the time ChatGPT arrived, clinical data-science teams had spent a decade working inside HIPAA, GDPR, FDA validation rules, and institutional review boards, and had built the machinery to ship AI under those constraints. Most of what the rest of the enterprise world is now encountering with generative AI (hallucinations in regulated workflows, unclear liability, compliance reviews that stall launches) healthcare has seen and has a pattern for. Four lessons from the way production medical AI gets built are directly transferable to finance, law, insurance, and any other sector where wrong answers have consequences.
Lesson 1: a complete view of the subject beats a clever model on a partial view
Most AI systems get built around whatever data is easiest to pull. In healthcare, that’s structured EHR fields: diagnoses, medications, labs, vital signs. A model trained on those fields can do useful things, but it misses most of the picture. More than half of the clinically relevant information about a patient (reasoning from the clinician, discussion with the patient, nuance about severity and certainty) lives in unstructured clinical notes, not in the coded fields. Add the PDFs (discharge summaries from other systems, external consults, prior-authorization letters), the medical images (radiology, pathology), and the patient-reported data (intake forms, symptom diaries), and the structured fields are maybe 30% of the available signal.
Production medical AI that works is built on top of a unified, longitudinal view of the patient that combines all of those sources. Structured demographics. Clinical characteristics. Vital signs. Smoking status. Past procedures and medications. Laboratory results. Extracted entities and assertions from progress notes. Findings from pathology and radiology reports. The combined view is what makes downstream tasks (disease progression prediction, clinical trial matching, cohort building, risk scoring) actually work. Models operating on the combined view routinely outperform ones that see only the structured slice of the record, because the unstructured slice is where most of the clinical reasoning happens to be written down.
The transfer is immediate:
- For a retail bank, the customer-completeness problem is the same shape. Transactions are structured. Call-center transcripts, chat logs, secure-message threads with relationship managers, and scanned-document submissions are not. A credit or churn model that sees only the structured side is working on a fraction of what’s available.
- For a property and casualty insurer, the claim is partly structured (coverage, policyholder, loss date) and heavily unstructured (adjuster notes, emails with claimants, photos, police reports, medical records). The systems that decide a claim well are the ones that read the full file.
- For a law firm, a case file is structured metadata plus mostly unstructured content: contracts, emails, depositions, exhibits. AI assistants that operate on that full file produce materially different answers than ones that see only the filing metadata.
In each case, the engineering pattern is the same: specialized extraction and classification models pull structured facts from unstructured sources, a harmonization layer joins them to the existing structured record, and downstream models (predictive, search, conversational) operate on the unified view. Healthcare built this pattern first because it had the worst unstructured-to-structured ratio. Every other regulated sector ends up building a version of it.
Lesson 2: the interface matters as much as the model
For a decade, advanced NLP and machine learning in regulated industries were gated on the availability of data scientists. If you wanted to train a model to extract contract clauses, detect adverse drug events, or classify claims, you needed an ML engineer to write code, a domain expert to label data, and a deployment team to push the result into production. That workflow scales poorly. There are not enough ML engineers for the work, and the domain experts with the relevant judgment (clinicians, pharmacists, lawyers, underwriters) are not going to learn Python on their own time.
Healthcare’s response to this bottleneck has been no-code annotation and human-in-the-loop tooling. The workflow that works in practice: a domain expert, working in a web UI, labels a small number of documents. An underlying system, often an LLM doing a zero-shot pass, proposes labels on the rest. The expert corrects the ones that are wrong. Those corrections become the next round of training data, which produces a smaller, faster, more accurate task-specific model. Iterate until the accuracy is where it needs to be, deploy the small model in production, keep the feedback loop running for monitoring and drift.
This compresses the build-and-validate loop from months to weeks, because the bottleneck, getting labeled data in the shape the specific task needs, is handled by the people who actually know what “correct” means. It also produces small, specialized models that are cheap to run at scale, rather than large general-purpose models called over an API at per-token cost. Regulatory requirements for human oversight and validation are satisfied by construction, because domain experts are signed into the loop at every step with audit trails, versioning, and approval workflows built in.
Other regulated industries are starting to build the same pattern for their own experts: lawyers labeling contracts for a contract-intelligence pipeline, compliance officers labeling transactions for anti-money-laundering models, underwriters labeling submissions for triage models. The model is secondary. The interface that lets the domain expert drive the process without writing code is what decides whether the project finishes.
Lesson 3: privacy and scale are architectural, not operational
In healthcare, “send the clinical notes to a third-party cloud API” is a non-starter for most organizations, most of the time. The reasons stack: HIPAA, GDPR, state privacy laws, institutional policy, patient expectations, data-sovereignty regulations in non-US jurisdictions. The result is that AI systems in healthcare have to be designed from the start to run inside the customer’s environment, on-premises, in the customer’s own private cloud tenant, or air-gapped, with no data ever leaving the customer’s control.
That constraint turns out to be a feature. In-environment deployment removes the per-token pricing model, because the customer is paying for compute they already own. It removes the latency tax of network round-trips to a vendor API. It removes most of the data-residency compliance questions, because the data never moved. It removes the vendor-lock-in risk that comes with building mission-critical pipelines on top of a third-party API whose pricing and availability the customer does not control. And it removes the training-data intellectual-property question, because the customer’s data stays the customer’s.
The architectural consequence is that healthcare AI systems are built to run efficiently on commodity hardware: single-GPU inference for most tasks, CPU inference for the lightweight ones, containerized deployment into Kubernetes or Databricks or Snowflake environments that customers already operate. This is a very different architecture from “call a vendor’s API from wherever,” and the difference matters for every other regulated industry that is going to face the same pressure.
Financial services is already there in parts — banks have regulatory constraints on where customer data can be processed, and many will not allow production workloads in third-party LLM APIs. Legal has similar constraints for privileged client information. Pharma has them for research data and trial records. In all of these sectors, the architectural pattern that scales is the one healthcare has already built: models designed to run in the customer’s environment, at production volume, on hardware the customer controls, with no data ever leaving.
The performance gap that used to make this architecture hard has mostly closed. Specialized domain-tuned models, carefully engineered for inference efficiency, now match or beat frontier LLMs on most of the specific tasks regulated industries care about, while running at 1–2% of the cost and with none of the compliance overhead. The remaining case for vendor APIs is for exploratory workloads and for conversational interfaces over curated knowledge — useful, but not where the production volume lives.
Lesson 4: humans in the loop are the accuracy mechanism, not a compliance afterthought
In regulated industries, 95% accuracy is not a success. It’s a system that still requires a human reviewer on every record, which is not automation. The target in healthcare for most high-volume tasks is above 99% — for de-identification, for PHI detection, for critical entity extraction — because that’s the threshold below which the downstream economics stop working. Hitting 99%+ on the first pass through a single model is rare. Hitting it through a composed system with a human-in-the-loop review layer is routine.
The pattern is a three-layer stack. The AI does the first pass at high volume and high speed. A confidence-scoring layer flags the records where the AI is uncertain, using calibrated confidence rather than raw model probabilities. A domain expert reviews only the flagged records, making the final call. The reviewed records feed back into the training set, so the AI gets steadily better over time and flags fewer records to the reviewers.
This pattern is what makes the economics work. If the AI runs at 96% accuracy and flags the 10% of records where it’s least confident, a human reviewer handling only those 10% is ten times as productive as a reviewer handling every record. If the AI’s confidence calibration is good, meaning the flagged records really are the ones where it’s most likely wrong, the combined system runs at well above 99%, faster and cheaper than either pure automation or pure manual review would be. The reviewers remain the accuracy mechanism; the AI just makes their throughput tractable.
Other regulated industries are arriving at the same architecture for the same reasons. Legal e-discovery review, insurance claims adjudication, financial compliance monitoring, pharma safety signal review — all of these have the same shape as clinical coding or adverse-event extraction. High volume, a regulatory requirement for human oversight, and an accuracy bar that no single model hits on its own. The systems that work are the ones that treat human review not as a compliance box but as an engineered throughput mechanism with measurable accuracy gains.
The short version for non-healthcare sectors
Four things to take from the way production medical AI gets built:
A complete view of the subject, combining structured and unstructured sources, tabular data and documents and images, is worth more than a clever model on a partial view. Build the harmonization layer first.
The domain experts who know what “correct” means should be driving the labeling and validation loop directly, through a no-code interface, with feedback that trains the model. That’s how projects actually finish.
Privacy and scale are architectural. Systems designed from day one to run in the customer’s environment, on the customer’s hardware, without data leaving, are cheaper, faster, and easier to clear compliance on than systems retrofitted to meet the same constraints later.
Human-in-the-loop is an engineering pattern, not a compliance concession. Calibrated AI confidence plus targeted expert review is how you hit the accuracy bars regulated workflows actually need, and it’s also how you make the economics work.
Healthcare’s head start was bought the hard way. The patterns it produced are available off the shelf to every other regulated industry that is now catching up.
FAQ
Why does healthcare keep coming up as a reference architecture for regulated AI?
Because healthcare had the hardest version of every constraint earliest: the strictest privacy rules, the highest accuracy bars, the worst unstructured-to-structured data ratio, and the most expensive wrong answers. The architectural patterns that cleared those bars (data harmonization, domain-expert-driven labeling, in-environment deployment, human-in-the-loop review) transfer to other sectors without much modification.
Does a unified longitudinal view always require OMOP or another formal common data model?
For research, RWE, and cross-institution work, formal common data models (OMOP, FHIR) are the right target because they make the data comparable across sources. For a single-organization operational use case, a payer running a model on its own claims and notes, or a bank running a model on its own customers, the same harmonization principles apply, but the target schema can be internal. The point is the harmonization, not the specific standard.
How is no-code annotation different from just giving domain experts a spreadsheet?
The tooling has to handle document-native labeling (highlighting spans of text inside a document rather than filling cells), manage annotator agreement across multiple reviewers, keep versioned datasets, integrate with model training so labels become training data automatically, and produce audit trails that satisfy regulatory review. A spreadsheet handles none of that.
What does “runs in the customer’s environment” mean technically?
Deployment of the models, the inference runtime, and often the training toolchain as software the customer installs into their own infrastructure: on-premises hardware, a private VPC in their AWS/Azure/GCP tenant, or an air-gapped environment. No data crosses the boundary to the vendor; no vendor-side API handles production inference. Licensing is typically fixed-cost rather than per-token.
How do you measure human-in-the-loop productivity gains?
Three numbers: the fraction of records the AI handles without review (throughput), the accuracy of the AI-only path on the records it passes (precision at high confidence), and the accuracy of the combined system on the flagged records (precision on the reviewed subset). A well-calibrated system improves on all three over time, because the feedback from reviewed records becomes training data for the next model version. That improvement loop is the operational KPI.