

Why the next useful medical chatbot will not look anything like ChatGPT

Originally published November 2023 in HIT Consultant and MedCity News.
The generation of medical chatbots built on top of frontier LLMs is topping out, and the ceiling is low. A system that answers “what are the contraindications for this medication” from a curated knowledge base is one thing. A system that answers “given what we know about this specific patient, should we switch them off this medication” is an entirely different architecture — and the architecture, not the LLM underneath it, is what decides whether the chatbot is usable in a clinical setting. The next wave of medical chatbots will read longitudinal patient records, reason over timelines, cite every answer, and run inside a hospital’s firewall. Very little of that work happens in the language model.
Where the first generation stalls
The Q&A chatbot pattern that took over 2023 has a fixed shape. A user asks a medical question in natural language. A retrieval layer pulls relevant passages from a reference corpus: guidelines, drug labels, medical textbooks, recent literature. The LLM is given those passages and the question, and it produces a paragraph of generated text. This is retrieval-augmented generation (RAG), and it works well for one class of problem: general medical reference. What is the recommended first-line therapy for uncomplicated community-acquired pneumonia? What are the renal dosing adjustments for vancomycin? What are the FDA-approved indications for semaglutide? RAG over a clean knowledge base handles these.
It handles almost nothing else a clinician actually needs to ask during a shift.
Consider the questions that come up in real clinical settings. “Is this patient a candidate for the new rheumatoid arthritis trial?” requires eligibility criteria to be matched against the patient’s actual history (diagnoses, medication failures, lab trends, comorbidities, prior treatments), most of which live in free-text clinical notes rather than structured fields. “Has this patient ever had a documented reaction to a sulfa drug?” requires reading through years of notes, recognizing that “rash after Bactrim in 2019” and “penicillin allergy noted by patient, tolerated amoxicillin in 2022” are different kinds of information, and returning a defensible answer with source pages cited. “Show me every patient in this panel who has uncontrolled diabetes and has missed two consecutive appointments” is not a language question at all — it’s a cohort query over longitudinal records, expressed in natural language because typing SQL in a clinic is absurd.
Each of these questions crosses a boundary that a frontier LLM with retrieval cannot handle on its own. The information needed to answer them lives in messy, patient-specific, multi-modal data (structured EHR fields, unstructured progress notes, scanned PDFs, medication lists, lab results), and the reasoning required spans time and combines sources. Dropping those inputs raw into a context window produces unreliable answers for the same reason dropping a hospital into a shoebox produces an unhelpful map.
What makes a medical chatbot work
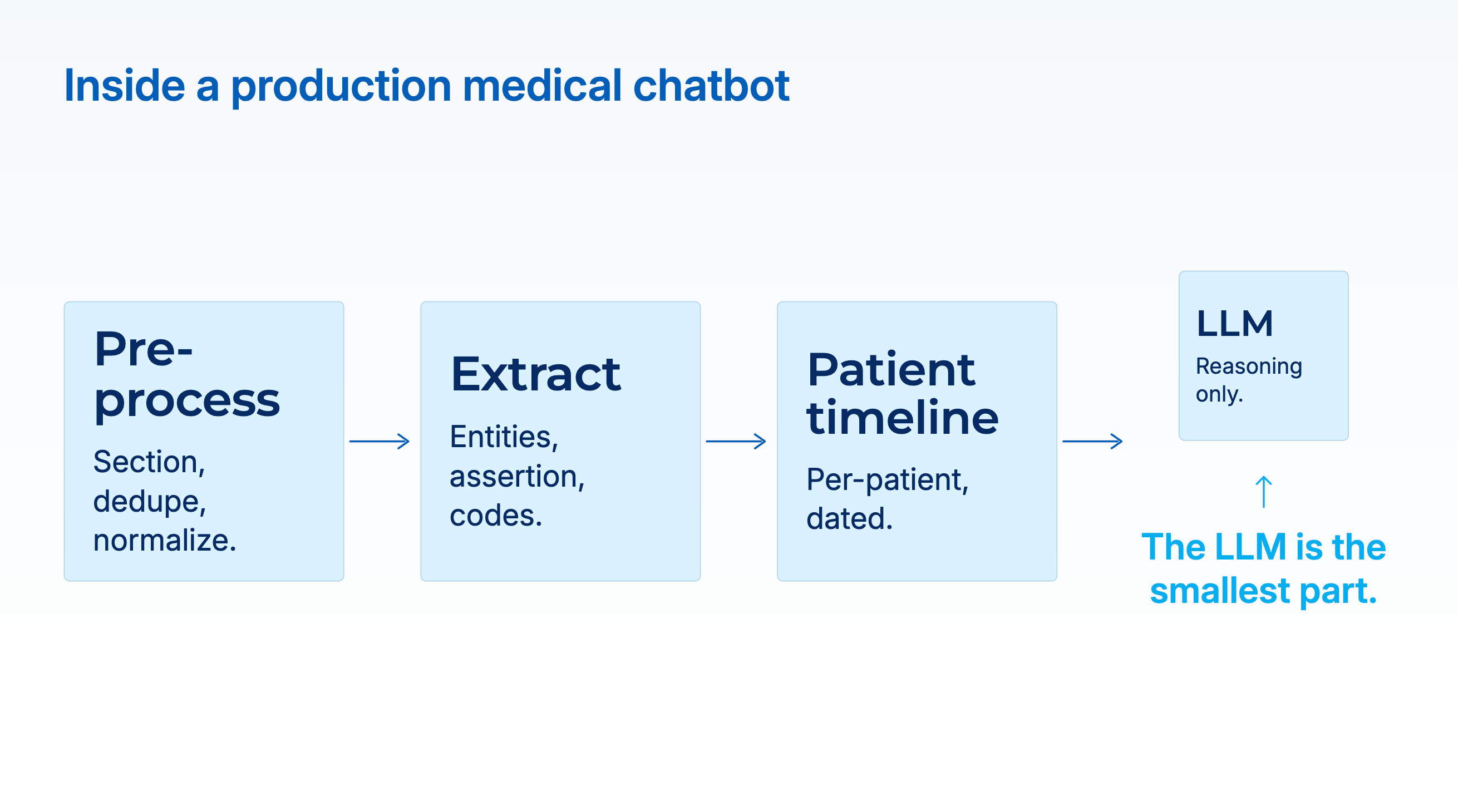
The architecture that handles the clinically useful questions looks different. The LLM is the smallest part of it. The heavy lifting is done by the layers beneath and around the language model, each doing a job the LLM should not be asked to do.
A healthcare-specific pre-processing pipeline. Real clinical text is roughly half copy-and-pasted content, with section headers (”Chief Complaint,” “History of Present Illness,” “Assessment and Plan”) that change the meaning of identical sentences depending on where they appear. A sentence saying “patient denies chest pain” in the HPI is a negation; the same sentence in the Assessment is a clinical decision. Before any reasoning happens, the system needs to section, de-duplicate, and normalize the note. General LLMs do not do this reliably. Specialized clinical-text pre-processing does.
Task-specific extraction models. Entity recognition, assertion status (is the condition present, absent, possible, or historical?), relation extraction (which medication caused which side effect?), and terminology mapping (resolving “MI” to “myocardial infarction” and then to ICD-10 I21 and SNOMED 22298006) are sequence-labeling and classification problems. Encoder models trained on domain data (PubMedBERT, BioClinicalBERT, and domain-tuned clinical models) consistently beat frontier LLMs on these tasks by material margins. A 2024 *JAMIA* study on the 2010 i2b2 concept-extraction benchmark measured BioClinicalBERT at F1 0.901 versus GPT-4 at 0.804 with baseline prompts; on the VAERS adverse-event corpus the gap was wider, 0.802 versus 0.593. The numbers decide what the downstream answer can be trusted to contain.
A longitudinal patient record. The extracted facts from dozens or hundreds of documents have to be assembled into a single per-patient timeline, with dates normalized, coreferences resolved across encounters, and a terminology that is stable across time. Only then can the system answer a question that requires knowing what happened and in what order. This is the step most demos skip.
A reasoning layer. Now the LLM earns its place. Given a structured, cited timeline as input, and a natural-language question, it can reason in the way people actually needed it to: comparing dates, weighing evidence, explaining its logic. The key is that it’s reasoning over clean, structured input rather than trying to simultaneously extract and reason over raw notes.
Citations on every answer. Every clinical answer the chatbot produces should point back to the specific document, section, and sentence that supports it. Without that, no clinician will trust it; with it, the chatbot stops being a black box and starts being a faster way to find source evidence. This is where regulatory-grade systems diverge from consumer chatbots: “the model said so” is not acceptable in a clinical workflow. “This patient’s creatinine was 1.9 mg/dL on the lab drawn 2026-01-14, as documented in the nephrology consult on that date (page 3)” is.
An in-environment deployment. Clinical notes cannot leave the hospital’s environment in most jurisdictions. HIPAA, GDPR, and the patchwork of state privacy laws that continue to accumulate put data sovereignty at the top of the compliance list. A chatbot that requires sending notes to a third-party cloud fails the procurement review before anyone looks at the accuracy numbers. On-premises or private-cloud deployment is not a premium feature; it is table stakes.
The shape of the next generation
The medical chatbots that clear the production bar are going to be compositions, not single models. Expect them to look roughly like this:
The user types a question. The system routes it: is this a general medical reference question, answerable from a curated knowledge base? Is it a patient-specific question that requires reasoning over this patient’s records? Is it a cohort question that requires running a query across a population? Each route has a different pipeline behind it.
For reference questions, RAG over a clinically curated knowledge base (drug labels, guidelines, peer-reviewed literature, the organization’s own protocols) with every answer citing its sources. For patient-specific questions, the pre-processing and extraction pipeline produces a structured view of the patient’s history, then the LLM reasons over that structured view. For cohort questions, the natural-language query is translated into a structured query over an OMOP-harmonized data warehouse, with the LLM used primarily as the translation layer between human language and database query. A 2024 benchmark looking at GPT-4 generating SQL queries for patient-level questions over structured health data found accuracy materially below what clinicians would tolerate in a production setting; task-specific translation models tuned on healthcare schemas did considerably better. This is an architectural point, not a model point: the LLM is part of the system, not the whole system.
Accuracy targets change by task. For reference Q&A, clinicians tolerate the same roughly 95% threshold they apply to a trusted colleague’s off-the-cuff answer, provided sources are cited and the system is upfront about uncertainty. For patient-specific extraction that feeds decisions, the bar is much higher: in practice, above 99% on de-identification and on assertion status, because below that, every answer needs human review and the automation value evaporates. The architecture has to know which bar it’s playing against, and the UI has to communicate that to the clinician using it.
Latency matters more than most demos acknowledge. A chatbot that takes 40 seconds to answer during a seven-minute patient encounter is a chatbot no one uses. Specialized models running on commodity hardware, rather than frontier LLMs called over the wire, are often what the latency budget will actually allow.
Expert evaluation is part of the build, not an afterthought. Technologists can get a medical chatbot roughly halfway; physicians, nurses, and pharmacists have to evaluate the generated answers on clinical relevance, style, consistency with current guidelines, and appropriateness for the setting. This is not a one-time certification; it’s an ongoing feedback loop, with disagreements from domain experts fed back into the training and evaluation sets. Any vendor claiming their chatbot is “clinician-approved” without describing that loop is selling a snapshot.
What this means for healthcare AI buyers
Three questions to ask when a vendor pitches a medical chatbot, each of which tends to separate production-grade systems from prototypes.
First: where do the answers come from, and how are they cited? A system that cannot show, for each answer, the specific source passages it is grounded in is not one that will clear clinical review. If the vendor’s demo answers cite nothing, the production system will cite nothing.
Second: what happens when the question requires reasoning over a specific patient’s record? If the answer is “we pass the chart to the LLM,” that’s the shoebox-map problem. If the answer involves a pre-processing pipeline, task-specific extraction, a structured patient timeline, and an LLM reasoning over the timeline, the vendor has built the architecture that actually works.
Third: where does the data live? On-premises, private cloud inside the buyer’s account, or third-party cloud? For most regulated healthcare organizations, only the first two answers are viable, and many procurement processes will not get past the third.
The next wave of medical chatbots will not be defined by which LLM is underneath. It will be defined by the architecture around the LLM: how the data is cleaned, how facts are extracted and verified, how timelines are assembled, how answers are cited, and where the whole thing runs. Healthcare organizations evaluating these systems get more signal from asking about the pipeline than from asking about the model.
FAQ
Isn’t a frontier LLM with a big enough context window eventually going to solve this?
Larger context windows help, but they don’t replace the upstream cleaning and extraction work. Clinical notes are too messy, too repetitive, and too full of specialty-specific language for raw ingestion to produce reliable answers, regardless of model size. The empirical pattern over the last two years has been that adding structure upstream of the LLM helps more than scaling the LLM does, for this class of problem.
How accurate do medical chatbots need to be for production use?
It depends on the task. For clinical reference Q&A, clinicians apply roughly the same bar they apply to a trusted colleague — accuracy in the mid-90s with clear source citations is usable. For patient-specific extraction that feeds decisions, the practical bar is above 99% on tasks like PHI removal and assertion status, because below that every output needs human review and the automation no longer saves time.
What’s wrong with RAG for medical chatbots?
Nothing — for the right question type. RAG over a curated knowledge base handles general medical reference questions well. It does not handle questions that require reasoning over a specific patient’s longitudinal record, because those questions need extracted, linked, timeline-aware patient data rather than retrieved passages. Those are different problems with different architectures.
Why is on-premises deployment treated as a requirement rather than a preference?
Because for most regulated healthcare organizations, HIPAA, GDPR, and the patchwork of US state privacy laws rule out sending clinical notes to third-party cloud services. In-environment deployment is a compliance requirement, not a performance preference. Systems that cannot run in the customer’s environment are usually eliminated before accuracy enters the conversation.
Are task-specific extraction models really still outperforming frontier LLMs, a full year after GPT-4?
On entity-level clinical extraction tasks (NER, assertion status, relation extraction, de-identification) yes, according to multiple peer-reviewed evaluations through 2024. On reference question-answering and summarization, frontier LLMs do well. The architecture trend is composition: specialized extraction models feeding clean structured data into frontier LLMs for the reasoning step.
David Talby is CEO of John Snow Labs. Its Medical LLM and Healthcare NLP libraries power medical chatbots and clinical information-extraction pipelines at 500+ healthcare and life sciences organizations. He also leads Pacific AI, which focuses on governance for healthcare AI.